AWS Neptune update: Machine learning, data science, and the future of graph databases | ZDNet
Data models and query languages are admittedly somewhat dry topics for people who are not in the inner circle of connoisseurs. Although graph data models and query languages are no exception to that rule, we’ve tried to keep track of developments in that area, for one main reason.
Graph is the fastest growing area in the biggest segment in enterprise software — databases. Case in point: A series of recent funding rounds, culminating in Neo4j’s $325 million Series F funding round, brought its valuation to over $2 billion.
Neo4j is among the graph database vendors who have been around the longest, and it now is the best-funded one, too. But that does not mean it’s the only one worth keeping an eye on. AWS entered the graph database market in 2018 with Neptune, and it has been making lots of progress since.
Today, AWS is unveiling support for openCypher, the open-source query language based on Neo4j’s Cypher. We take the opportunity to unpack what this means, and how it’s related to the future of graph databases, as well as revisit interesting developments in Neptune’s support for machine learning and data science.
Building bridges with openCypher
Developers can now use openCypher, a popular graph query language, with Amazon Neptune, providing more choice to build or migrate graph applications. Neptune now has support for the top three most popular graph query languages: Cypher, Gremlin, and SPARQL.
In addition, Neptune will be adding support for Bolt, Neo4j’s binary protocol. What this hints at is the ability to allow customers to leverage familiar and existing tooling — Neo4’s tooling, to be more specific. But there are more reasons why this is important.
There are two main data models used to model graphs: RDF and Labeled Property Graph (LPG). Neptune supports both, with SPARQL serving as the query language for RDF, and Gremlin serving as the query language for LPG. Gremlin has a lot going for it, as it has nearly ubiquitous support, and offers a lot of control over graph traversals. But that can also be a problem.
Gremlin, part of the Apache Tinkerpop project, is an imperative query language. This means that as opposed to declarative query languages like SQL, Cypher, and SPARQL, Gremlin queries don’t just express what to retrieve, but they also need to specify how. In that respect, Gremlin is more akin a programming language.
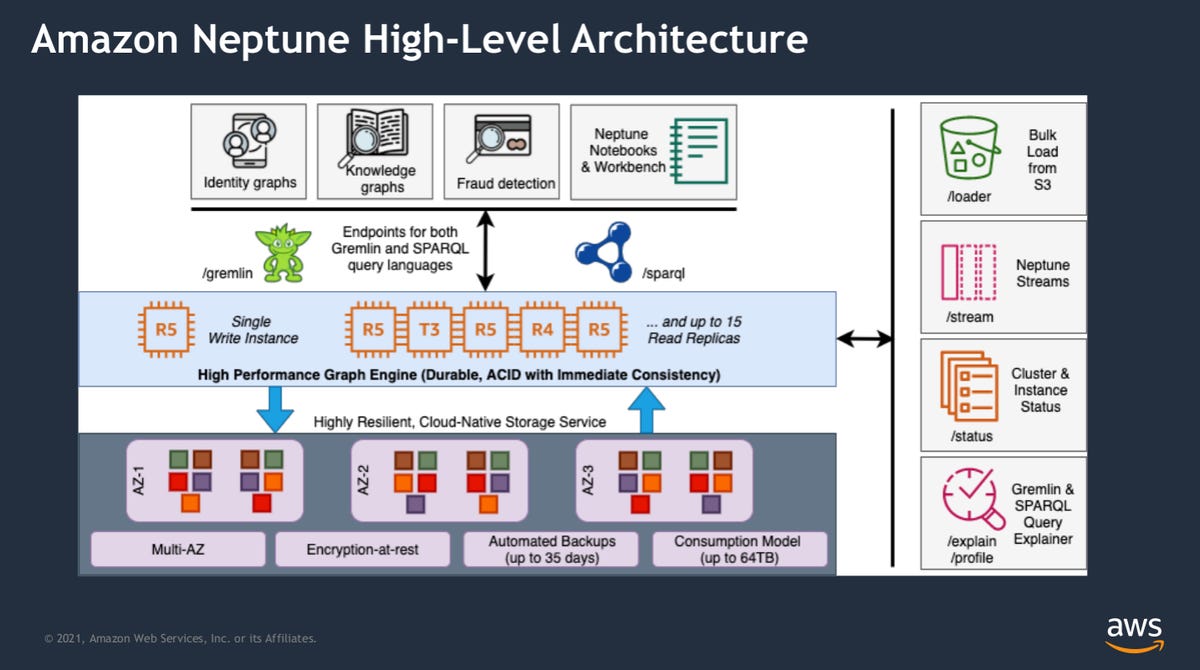
Amazon Neptune architecture. Neptune’s capabilities are now enhanced by its support for openCypher, which brings more flexibility to its arsenal.
AWS
Not all users are comfortable using Gremlin in all scenarios. If they wanted to use the LPG model, however, that was all they had to go by. Amazon, despite employing some key contributors to Apache Tinkerpop, seems to acknowledge this. Adding support for openCypher makes working with the LPG engine in Neptune more approachable.
Neptune’s support for LPG and RDF is possible because it hosts two different engines under its hood, one for each data model. Adding support for openCypher does not change that — at least not yet. But RDF* might. RDF*, also known as RDF Star, is an update to the RDF standard that enables it to model LPG graphs too.
There is ongoing work in that area in both RDF and LPG working groups. Besides Amazon with Neptune, other RDF vendors are also adding experimental support for openCypher. The bigger picture here is the ongoing work, endorsed by the ISO, on GQL.
GQL is a new standard for graph query languages, aiming to unify what is today a fragmented landscape. The expectation is that GQL will do for graph databases what SQL did for relational databases. Amazon is active in both the RDF* and GQL efforts.
Eventually, that should enable Neptune to unify its two currently disparate engines. But the story here is bigger than just Amazon. The promise is that what Amazon will be able to do under the hood, all graph database users should be able to do across their systems: use a single data model and a single query language.
Data science and machine learning features: Notebooks and Graph Neural Networks
GQL still has some way to go. Standardization efforts are always complicated, and adoption is not guaranteed across the board either. But Neptune also exemplifies another important development in graph databases: integration of data science and machine learning features.
Developing graph applications, and navigating graph results, is greatly facilitated by IDEs and visual exploration tools tailored to this purpose. While many graph database vendors have incorporated built-in tools for those purposes in their offerings, Neptune was relying exclusively on third party integrations until recently.
The way Neptune’s team chose to address this gap was by developing AWS Graph Notebook. Notebooks are very popular among data scientists and machine learning practitioners, enabling them to mix and match code, data, visualization, and documentation, and to work collaboratively.
AWS Graph Notebook is an open source Python package for Jupyter notebooks to support graph visualization. It supports both Gremlin and SPARQL, and we expect it will eventually support openCypher, too. While initially adopted by the data science and machine learning crowds, Amazon seems to believe notebooks will also catch on among developers.
Neptune ML is the code name Amazon has given to the integration between its Neptune graph database and graph machine learning capabilities in SageMaker and DGL.
AWS
We’ll have to wait to see if that bet pays off. What is certain, however, is that offering notebook support strengthens Neptune’s appeal for data science and machine learning use cases. But that’s not all Neptune has to offer there — enter Neptune ML.
Amazon touts Neptune ML as a way to make easy, fast, and accurate predictions on graphs with graph neural networks (GNNs). Neptune ML is powered by Amazon SageMaker and the open source Deep Graph Library (DGL), to which Amazon contributes.
GNNs is a relatively new branch of Deep Learning, with the interesting feature that they leverage the additional contextual information that modeling data as a graph can model to train Deep Learning algorithms. GNNs is considered state of the art in machine learning, and they can have better accuracy in making predictions compared to conventional neural networks.
Integrating GNNs with graph databases is a natural match. GNNs can be used for node-level and edge-level predictions, i.e. they can infer additional data and connections in graphs. They can be used to train models to infer properties for use cases like fraud prediction, ad targeting, customer 360, recommendations, identity resolution, and knowledge graph completion.
Again, Neptune is not the only one to incorporate notebooks and machine learning in its offering. Besides addressing the data science and machine learning crowd, these features can also upgrade the developer and end-user experience as well. Better tools, better data, better analytics — they all result in better end-user applications. That’s what all vendors are striving for.
For all the latest Technology News Click Here
For the latest news and updates, follow us on Google News.